🥲 문제 상황
현재 진행하고 있는 프로젝트에서 업로드된 파일의 MIME Type을 활용하여 “IMAGE”, “FILE”, “VIDEO”로 구분할 수 있도록 아래와 같이 Enum을 활용하였다.
현재는 총 23개의 Type을 생성해 놨지만, 추후 더 추가될 가능성도 있다.

내가 원하고자 하는 바는 인자(Argument)로 mimeType을 입력하면, 해당 콘텐츠 타입의 keyMediaType(”IMAGE”, “FILE”, “VIDEO” 중 하나)를 반환하는 것이다.
아래의 그림에 구현된 코드를 보면 기존에 나는 Arrays.stream() 을 활용하여 Enum의 모든 요소를 순회하면서 조건에 맞는 요소를 찾는 방식이었다.

위 방법의 시간복잡도는 O(n)이다. 현재 내가 작성한 요소의 개수가 23개라면, 최악의 경우에 23번째까지 순회해야 원하는 결과를 얻을 수 있다는 의미이다.
서비스의 규모가 커지지 않고 요소의 개수가 적으며 한정적이라면 괜찮겠지만, 서비스의 규모가 커져 요소의 개수가 더욱 늘어나고 사용자의 수도 증가한다면 무시할 수 없는 문제이다.
✍️ 해결 방법
해결 방법은 간단하다. Map을 활용하여 시간복잡도를 거의(?) O(1)로 만드는 것이다.
=번외=
거의라고 말한 이유는? HashMap에 대하여!!
거의라고 말한 이유는 Java에서 제공하는 HashMap은 데이터를 저장할 때 객체의 hashcode()를 사용한다는 점 때문이다. HashMap은 해당 hashcode의 값을 사용하여 저장할 배열의 특정 인덱스를 결정한다. 하지만 hashcode의 값이 같을 경우(Hash Collision)에 HashMap은 **Separate Chaining (분리 연결법)**과 Treeify (트리화) 두 가지 알고리즘을 활용하여 해결한다.
간단하게 설명하면 하나의 인덱스에 여러 개의 key-value 쌍을 저장하게 해주는 것이다.
저장하는 방법을 위 두 알고리즘을 사용한 것인데, 첫 번째로 LinkedList에 key-value 를 저장하며 관리하고, 두 번째로 저장된 요소가 8개가 넘어간다면 검색 성능을 향상하기 위해 Red-Black 트리로 변환하여 저장한다.
위와 같은 해시 충돌 처리 방법 때문에, 만약 해시 충돌이 많은 경우 HashMap의 조회 시간 복잡도는 O(1)을 지킬 수가 없게되고, 연결 리스트 혹은 트리를 순회하는 비용이 추가적으로 들게 되는 것이다.
최악의 경우 O(n)이 될 수 있지만, 대부분의 경우 O(1)에 가깝기 때문에
항상 O(n)이 되는 filter()를 사용하는 것보다 성능이 더 좋다.
====
위의 예시를 이어 설명하면, 먼저 mimeType을 key로 Enum의 요소를 value로 구성되는 Map 객체를 생성한다. Enum의 요소로 정의하는 것은 보통 상수이기 때문에 수정할 수 없는 Map을 생성하기 위해 Collectors.toUnmodifiableMap() 을 활용한다.

그다음 해당 Map을 활용하여 ContentType을 조회하는 메소드를 만들어준다.

끝! 위처럼 구현을 마친뒤 해당 메소드를 사용하면 거의 O(1)을 보장하는 조회 성능으로 개선될 수 있다.
😄 성능 비교
가장 중요하고 재미있는 부분인 성능 비교이다!
또한, 수치로 표현하고 직접 눈으로 확인해야 더욱 잘 받아들여진다.
아래는 실험에 사용된 코드이다.
public static void main(String[] args) {
final int iterations = 100000;
String[] testMimeTypes = {"application/octet-stream", "text/html", "application/pdf", "video/mp4", "unknown/type"};
//O(N)
long streamStart = System.nanoTime();
for (int i = 0; i < iterations; i++) {
for (String mimeType : testMimeTypes) {
try {
String contentType = ContentType.findByMimeTypeWithArray(mimeType);
} catch (IllegalArgumentException e) {
// 예외는 무시
}
}
}
long streamEnd = System.nanoTime();
System.out.println("O(N) 걸린 시간: " + (streamEnd - streamStart) / 1000000.0 + " ms");
// Map 측정
long mapStart = System.nanoTime();
for (int i = 0; i < iterations; i++) {
for (String mimeType : testMimeTypes) {
try {
ContentType.findByMimeTypeWithMap(mimeType);
} catch (IllegalArgumentException e) {
// 예외는 무시
}
}
}
long mapEnd = System.nanoTime();
System.out.println("O(1) 걸린 시간: " + (mapEnd - mapStart) / 1000000.0 + " ms");
}
실험은 총 2가지 경우의 수를 따져봤다.
첫 번째는 10만 회 해당 메소드를 사용할 경우
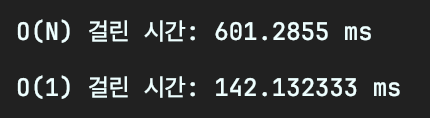
반복문을 사용했을 경우 약 0.6초가 소요되었고, Map을 사용했을 경우 약 0.14초가 소요되었다.
두 번째는 100만 회 해당 메소드를 사용할 경우
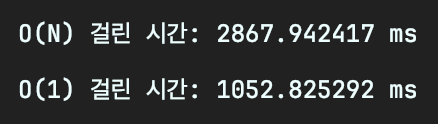
반복문을 사용했을 경우 약 2.8초가 소요되었고, Map을 사용했을 경우 약 1.0초가 소요되었다.
결론
10만 회를 사용했을 경우 소요된 시간의 차이는 약 0.46초이고, 100만 회를 사용했을 경우 소요된 시간의 차이는 약 1.8초이다.
점점 늘어나는 수치를 확인할 수 있고 의미 있는 성능 개선이라고 볼 수 있다.
간단한 자료구조를 사용하여 성능을 개선할 수 있다는 점에서 재밌었고, 단순한 로직도 가볍게 여기지 말고 사용 이유와 개선 방법에 대해 신중한 고민을 하는 것이 좋을 것 같다.
'JAVA' 카테고리의 다른 글
| Arrays.asList()와 List.of()의 차이 (0) | 2024.09.30 |
|---|---|
| stream.toList() 와 .collect(Collectors.toList()) 차이 (0) | 2024.09.30 |
| Enum (1) | 2023.09.15 |
| equals()와 hashcode() (1) | 2023.09.06 |


